visionpro
https://www.cognex.cn/zh-cn/products/machine-vision/vision-software/visionpro-software
https://www.cognex.cn/zh-cn/products/machine-vision/vision-software/visionpro-software
源码
https://github.com/jrosebr1/imutils
参考
https://www.jianshu.com/p/bb34ddf2a947
https://www.pythonf.cn/read/30985
图形矫正 http://www.mamicode.com/info-detail-2802340.html
查看版本等信息
pinout
cat /proc/cpuinfo
cat /proc/device-tree/model
开启ssh
根目录放置空文件ssh
开机接入无线
country=CN
ctrl_interface=DIR=/var/run/wpa_supplicant GROUP=netdev
update_config=1
network={
ssid="ssid"
psk="pwd"
priority=99
}
查看针脚 gpio readall
#include <wiringPi.h>
#include <softPwm.h>
https://www.cnblogs.com/lulipro/p/5992172.html
然后运行项目,OK允许
bash的配置文件是 -/.bash_profile
zsh的配置文件是-/.zshrc
安装iTerm2
iTerm2下载地址:https://www.iterm2.com/downloads.html
brew cask install iterm2
安装oh my zsh
通过curl安装:
sh -c “$(curl -fsSL https://raw.githubusercontent.com/ohmyzsh/ohmyzsh/master/tools/install.sh)”
或通过wget安装:
sh -c “$(wget -O- https://raw.githubusercontent.com/ohmyzsh/ohmyzsh/master/tools/install.sh)
‘/Applications/IntelliJ IDEA.app/Contents/MacOS/idea’
显示图像
None = cv2.namedWindow(winname) 创建指定名的窗口
None = cv2.imshow(winname,img)
等待按键
retval = cv2.waitKey([delay])
retval 按键返回值按键的ASCII码,没有按键-1
delay 等待键盘触发时间ms,0或负数,一直等待,默认0
获取字符的ASCII码值
ord(“A”)
销毁指定的窗口
None = cv2.destroyWindow(winname)
销毁所有的窗口
None = cv2.destroyAllWindow()
保存图像
retval = cv2.imwrite(filename,img[,params])
retval 保存结果True False成功或失败
filename 要保存的完整文件名
img 被保存的图像
params 保存的类型参数
最小数据类型无符号的8位数
二值图像转为特殊的灰度图0黑色255白色
opencv 通道顺序 BGR 与RGB相反,img[:,:,0] B通道 img[:,:,1] G通道 img[:,:,2] R通道
numpy.array更快的访问像素
item(行,列)
itemset(索引值,新值) 索引值=(行,列)
感兴趣区域ROI
img[200:400,200:400]
通道拆分
b = img[:,:,0]
g = img[:,:,1]
r = img[:,:,2]
b,g,r = cv2.split(img)
b = cv2.split(img)[0]
g = cv2.split(img)[1]
r = cv2.split(img)[2]
获取图像的属性
img.shape 返回行数,列数,通道数,如是二值图或灰度图,只有行列数
img.size 返回像素数目,行数列数通道数,如是二值图或灰度图,通道数为1
img.dtype 返回图像的数据类型
图像的加法
a+b的和除以256
cv2.add(a,b[,mask]) 和大于255,取值255
图像加权和
dst = cv2.addWeighted(src1,alpha,src2,beta,gamma)
dst=src1alpha+src2beta+gamma
按位与
dst = cv2.bitwise_and(src1,src2[,mask])
mask 8位单通道array值,常用于保留掩模内的图像
按位或
dst = cv2.bitwise_or(src1,src2[,mask])
按位异或
dst = cv2.bitwise_xor(src1,src2[,mask])
按位取反 非
dst = cv2.bitwise_not(src1,src2[,mask])
位平面分解
阀值处理
mask = img[:,:,i]>0 将图像中大于0的值处理为True <=0的处理为 False
img[mask] = 255 将True替换为255,False替换为0
opencv提像了专门的阀值处理函数cv2.threshold()
图像加解密,水印
加密: 明文A与密钥B异或,得到密文C
解密:密文C与密钥B异或,得到明文A
水印在最低有效位LSB隐藏信息,对整体图像影响不明显
类型转换
dst = cv2.cvtColor(src, code[,dstCn])
dst 转换后的图像,与原图具有同样的数据类型各深度
src 要转换的原图
code 色彩空间转换码
dstCn 目标通道数,默认0,自动通过原始输入图和code得到

更多类型查看官网
alpha通道
RGBA色彩空间4通道,alpha通道值[0,1]或[0,255]表示从透明到不透明
缩放
dst = cv2.resize(src,dSize[,fx[,fy[,interpolation]]])
dst 输出的图像,类型与src相同,大小为dSize(非0时)或通过计算得到
src 要缩放的图像
dSize 输出图像大小,为None时能过缩放比计算
fx 水平方向的缩放比
fy 垂直方向的缩放比
interpolation 插值方式 在缩小图像时,使用区域插值方式能有好的效果cv2.INTER_AREA,放大图像时,使用三次样条INTER_CUBIC(慢)和双线性INTER_LINEAR插值效果不错(快)
翻转
dst = cv2.flip(src, flipCode)
flipCode 旋转类型0绕着X轴翻转,正数绕着y轴,负数绕着x,y轴同时翻转
仿射
dst(x,y) = src(M11x+M12y+M13,M21x+M22y+M23)
dst = cv2.warpAffine(src,M,dSize[,flags[,borderMode[,borderValue]]])
M 2X3的变换矩阵,使用不同的矩阵,实现不同的仿射变换
dSize 输出图像的大小
flags 插值方式,默认INTER_LINEAR,为WARP_INVERSE_MAP时,M是逆变换类型
borderMode 代表边类型,默认BORDER_CONSTANT,目标图像内值不做改变,对应原始图像内的异常值
borderValue 边界值,默认为0
平移M
dst(x,y) = src(x+100,y+200)
M = np.float32([1,0,100],[0,1,200])
旋转M
M = cv2.getRotationMatrix2D(center,angle,scale)
center 旋转的中心点
angle 旋转的角度,正表示逆时针,负表示正时针旋转
scale 放大缩小变换尺度
复杂变换M
M = cv2.getAffineTransform(src,dst)
src 输入图像的三个顶点坐标
dst 输出图像的三个顶点坐标
透视变换,可以将矩形应射为任意四边形
dst = cv2.warpPerspective(src,M,dSuze[,flags[,borderMode[,borderValue]]])
M 3X3的变换矩阵,使用不同的矩阵,实现不同的仿射变换
dSize 输出图像的大小
flags 插值方式,默认INTER_LINEAR,为WARP_INVERSE_MAP时,M是逆变换类型
borderMode 代表边类型,默认BORDER_CONSTANT,目标图像内值不做改变,对应原始图像内的异常值
borderValue 边界值,默认为0
构造M函数
M = cv2.getPerspectiveTransform(src,dst)
src 输入图像的四个顶点坐标
dst 输出图像的四个顶点坐标
重映射
dst = cv2.remap(src,mapX,mapY,interpolation[,borderMode[,borderValue]])
mapX 参数有两种可能表示(x,y)点的一个映射 表示CV_16SC2,CV_32FC1,CV_32FC2类型(x,y)点的x值
mapY 当map1表示(x,y)时,值为空,(是x,y)点的x值时,是CV_16UC1,CV_32FCL1类型(x,y)点的y值
interpolation 插值方式,不支持INTER_LINEAR方法
borderMode 边界模式
borderValue 边界值,默认0
可以实现复制,翻转,缩放等操作
retval, dst = cv2.threshold(src,thresh,maxval,type)
retval 返回的阀值
dst 阀值分割结果图像
thresh 设定的阀值
maxval 当type设定为THRESH_BINARY,THRESH_BINARY_INV时,需要设定最大值
type cv2.THRESH_BINARY 二值化阀值处理 THRESH_BINARY_INV反二值化阀值处理 THRESH_TRUNC截断阈值化处理 THRESH_TOZERO_INV超阈值零处理 THRESH_TOZERO 低阈值零处理
自适应阈值处理 能更好的处理明暗差异较大的图像
dst = cv2.adaptiveThreshold(src,maxValue,adaptiveMethod,thresholdType,blockSize,C)
maxValue 最大值
adaptiveMethod 自适应方法
thresholdType 阀值处理方式,只能是THRESH_BINARY,THRESH_BINARY_INV
blockSize 领域尺寸的块大小,通常3,5,7等
C 常量
Otsu处理 根据图像给出最佳的类间分割阈值
retval, dst = cv2.threshold(src,0,255,cv2.THRESH_BINARY + cv2.THRESH_OTSU)
retval 返回的最优阀值
dst 阀值分割结果图像
均值滤波
dst = cv2.blur(src,ksize,anchor,borderType)
dst 滤波后的结果
src 待处理的图像
ksize 滤波核的大小,领域图像的高度和宽度,如(3,3)
anchor 锚点,默认(-1,-1),表示当前计算的均值点位于核的中心点位置,一般默认即可
borderType 边界样式,一般不用考虑取值,默认即可
方框滤波
dst = cv2.boxFilter(src,ddepth,ksize,anchor,normalize,borderType)
dst 滤波后的结果
src 待处理的图像
ddepth 图像处理深度,一般用-1,表示与原图像同样深度
ksize 滤波核的大小,领域图像的高度和宽度,如(3,3)
anchor 锚点,默认(-1,-1),表示当前计算的均值点位于核的中心点位置,一般默认即可
normalize 是否进行归一化
borderType 边界样式,一般不用考虑取值,默认即可
高斯滤波 考虑权重
dst = cv2.GaussianBlur(src, ksize, sigmaX, sigmaY,borderType)
sigmaX 卷积核在水平方向X的标准差
sigmaY 卷积核在垂直方向Y的标准差 ,为0,则只采用sigmaX的值,sigmaX也为0,则通过ksize自动计算
中值滤波
dst = cv2.medianBlur(src, ksize)
ksize 核大小,比1大的奇数,3,5,7…
双边滤波 有效保护图像内的边缘信息
dst = cv2.bilateralFilter(src,d,sigmaColor,sigmaSpace,borderType)
d 空间距离参数,表示以当前像素点为中心点的直径.为负数,自动从sigmaSpace计算得到,如果>5,速度较慢,一般推荐5,对于较大噪声的离线滤波,可以用9
sigmaColor 颜色差值范围,决定周围哪些像素点能够参与到滤波中来.小于sigmaColor的像素点可以参与,255都可以
sigmaSpace 坐标空间中的sigma值,越大越有更多的值参与运算.d>0时,d指定领域大小
2D卷积 自定义
dst = cv2.filter2D(src, ddepth,kernel,anchor,delta,borderType)
delta 修正值,可选项
以9*9大小领域进行均值滤波 1/81 kernel = np.ones((9,9),np.float32)/81
腐蚀 图像的边界点消除,向内收缩
dst = cv2.erode(src , kernel [, anchor [, iterations [, borderType[, borderValue]]]])
kernel 腐蚀操作的结构类型,可以自定,可以cv2.getStructuringElement()生成
anchor element结构中锚点的位置,默认(-1,-1),要核的中心位置
iterations 迭代次数,默认1
borderType 边界样式,默认BORDER_CONSTANT
borderValue 边界值,一般默认,C++中提供morphologyDefaultBorderValue()返回腐蚀和膨胀的magic边界值
膨胀 对图像边界扩张,还可以消除内部斑点
dst = cv2.dilate(src , kernel [, anchor [, iterations [, borderType[, borderValue]]]])
能用形态学函数
dst = cv2.morphologyEx(src ,op, kernel [, anchor [, iterations [, borderType[, borderValue]]]])
op cv2.MORPH_ERODE 腐蚀erode(src)
..DILATE 膨胀 dilate(src)
..OPEN 开运算 dilate(erode(src)) 用于去噪,分割,计数
..CLOSE 闭运算 erode(dilate(src)) 用于关闭前景内部小孔,去除物体上的小黑点,进行图像连接
..GRADIENT 梯度运算 dilate(src)-erode(src) 可以获得前景图像的边缘
..TOPATH 顶帽运算 src-open(src) 获取图像的噪声信息,或得到比原始图像边缘更亮的边缘信息
..BLACKHAT 黑帽运算 close(src) -src 获取图像内部小孔,或前景中的小黑点,,或得到比原始图像边缘更暗的边缘信息
..HITMISS 击中击不中 intersection(erode(src),erode(srcI))
构造核函数
retval = cv2.getStructuringElement(shape,ksize[,anchor])
shape 形状类型 cv2.MORPH_RECT 矩形结构元素,都是1 ..CROSS 十字形结构元素,对角线为1 .. ELLIPSE 椭圆形结构元素
ksize 结构元素的大小
anchor 结构中锚点的位置,默认(-1,-1),要核的中心位置
sobel算子 在离散空间,可能不太准确
dst = cv2.Soble(src,ddepth,dx,dy[,ksize[,scale[,delta[,borderType]]]])
ddepth 输出图像的深度 输入图像的深度cv2.CV_8U ..16U/16S ..32F ..64F 输出深度为1/输入图像深度,再计算时为避免信息丢失,先设为cv2.CV_64F,再通过取绝对值映射为cv2.CV_8U.
dx x方向的求导阶数
dy y方向的求导阶数
x方向边缘,dx=1,dy=0 y方向边缘,dx=0,dy=1 ,xy方向重合的部分dx=1,dy=1 ,xy方向叠加cv2.addWeighted(),注意先取绝对值
ksize sobel核的大小.-1会使用Scharr算子进行运算
scale 缩放因子,默认为1,不缩放
delta 加在目标图上的值 ,默认为0
borderType 边界样式
取绝对值
dst = cv2.convertScaleAbs(src[, alpha[, beta]])
alpha 调节系数,默认为1
beta 调节亮度值,默认为0
Scharr算子 同样速度且精度更高
dst = cv2.Scharr(src,ddepth,dx,dy[,scale[,delta[,borderType]]])
ddepth 为cv2.CV_64F,再通过取绝对值映射为cv2.CV_8U
dx,dy x方向边缘,dx=1,dy=0 y方向边缘,dx=0,dy=1 ,xy方向叠加cv2.addWeighted(),只有这三种方式
Laplacian算子 具有旋转不变性,满足不同方向图像边缘检测的要求
dst = cv2.Laplacian(src,ddepth,[,ksize[,scale[,delta[,borderType]]]])
ksize 核尺寸大小,必须为正奇数
计算结果必须取绝对值才能保证正确
Canny边缘检测
edges = cv2.Canny(image,minThreshold,maxThreshold[,apertureSize[,L2gradient]])
edges 返回的边缘图像
image 8位输入图像
minThreshold 第一个小的阈值
maxThreshold 第二个大的阈值 minThreshold,maxThreshold较小时能检测更多的结果
apertureSize Sobel算子的孔径大小
L2gradient 计算梯形副度的标识,默认为False,使用L1范数计算,为True时使用更精确的L2范数计算
高斯金字塔 向下采样
dst = cv2.pyrDown(src[,dstsize[,borderType]])
dstsize 目标图像大小,默认情况下输出大小为Size((src.cols+1)/2,(src.rows+1)/2)
borderType 办界类型,仅支持BORDER_DEFAULT
高斯金字塔 向上采样
dst = cv2.pyrUp(src[,dstsize[,borderType]])
dstsize 目标图像大小,默认情况下输出大小为Size(src.cols2,src.rows2)
borderType 办界类型,仅支持BORDER_DEFAULT
两个方向操作不可逆
拉普拉斯金字塔 可获得采样过程中丢失的信息
Li = Gi – pyrUp(Gi+1)
Li 拉普拉斯金字塔的第i层
Gi 高斯金字塔的第i层
查找图像轮廓
image, contours, hierarchy = cv2.findContours(image, mode, method)
CV4 contours, hierarchy = cv2.findContours(image, mode, method)
contours 返回的轮廓数组
hierarchy 轮廓的层次关系
image 必须是8位单通道二值图像
mode cv2.RETR_EXTERNAL 只检测外轮廓 cv2.RETR_LIST不建立等级关系cv2.RETR_CCOMP 两级层次结构 cv2.RETR_TREE 建立等级树的层次结构
绘制图像轮廓
image = cv2.drawContours(image,contours,contourIdx,color[,thickness[,lineType[,hierarchy[,maxLevel[,offset]]]]])
contours 图像轮廓
contourIdx 轮廓索引 -1绘制全部轮廓
color 绘制颜色
thickness 画笔粗细 -1绘制实心轮廓,即特定对象的掩模
lineType 绘制的线型
hierarchy 轮廓的层次关系
maxLevel 轮廓的层次深度 0仅绘制第0层,其它非0整数,绘制最高层及以下相同数量层级的轮廓
offset 偏移参数,将轮廓偏移到不同的位置展示出来
轮廓矩特征 用来比较两个轮廓是否相似
retval = cv2.moments(array[,binaryImage])
array 可以是点集,灰度图,二值图
binaryImage 为True时,array所有非零值都被处理为1,此值仅在array为图像时有效
retval 特征矩 空间矩:零阶矩m00表示轮廓的面积 中心矩: 归一化中心矩:
计算轮廓的面积
retval = cv2.contourArea(contour[,oriented])
contour 轮廓
oriented 默认False,返回绝对值 为True是返回值包含正负号,表示轮廓是顺时针还是逆时针的
计算轮廓的长度
retval = cv2.arcLength(contour,closed)
contour 轮廓
closed True/False 轮廓是否封闭
Hu矩–用来识别图像的特征
hu = cv2.HuMoments(m);
hu h0~h6
m cv2.moments计算得到的矩特征值
形状匹配
retval = cv2.matchShapes(contour1,contour2,method,parameter)
contour1 contour2 两个轮廓或者灰度图像
method 比较方法 cv2.CONTOURS_MATCH_I1(2/3)
parameter 扩展参数到CV4.1.0暂都不支持,应设为0
轮廓拟合-矩形包围框
retval = cv2.boundingRect(array)
x,y,w,h = cv2.boundingRect(array)
retval x,y,w,h 矩形边界左上角顶点坐标值及边界的宽度和高度
array 灰度图像或轮廓
轮廓拟合-最小包围矩形框
retval = cv2.minAreaRect(points)
retval (最小外接矩形的中心(x,y),(宽度,高度),旋转角度)
points 轮廓
retval返回值不符合cv2.drawContours参数结构,需使用cv2.boxPoints()转换
转换轮廓 获取最小包围矩形框的四个顶点坐标
points = cv2.boxPoints(box)
points 能使用cv2.drawContours绘制的轮廓点
box cv2.minAreaRect的返回值
轮廓拟合-最小包围圆形
center, radius = cv2.minEnclosingCircle(points)
(x,y), radius = cv2.minEnclosingCircle(points)
center 最小包围圆形的中心
radius 半径
points 轮廓
轮廓拟合-最优拟合椭圆
retval = cv2.fitEllipse(points)
retval 是RotatedRect类型,包括质心,宽,高,旋转角度等信息
points 轮廓
轮廓拟合-最优拟合直线
line = cv2.fitLine(points,distType,param,reps,aeps)
[vx,vy,x,y] = cv2.fitLine(points,distType,param,reps,aeps)
points 轮廓
distType 距离类型,要使输入点到拟合直线的距离之和最小,如下:
cv2.DIST_USER/L1/L2/C/L12/FAIR/WELSCH/HUBER
param 距离参数 与所选距离类型有关, 为0时自动选择最优
reps 径向精度,通常设为0.01
aeps 角度精度,通常设为0.01
轮廓拟合-最小外包三角形
retval,triangle = cv2.minEnclosingTriangle(points)
retval 最小外包三角形的面积
triangle 最小外包三角形的三个顶点
轮廓拟合-逼近多边形-采用的是DP算法
approxCurve = cv2.approxPolyDP(curve,epsilon,closed)
approxCurve 逼近多边形的点集
curve 轮廓
epsilon 精度 原始轮廓的边界点与逼近多边形边界之间的最大距离,通常设为多边形总长度的百分比形式
closed True/False 多边形是否封闭的
凸包
hull = cv2.convexHull(points[,clockwise[,returnPoints]])
points 轮廓
clockwise True/False 凸包角点按顺时针或逆时针方向排列
returnPoints True/False 默认为True,返回凸包角点的x/y坐标,反之返回角点的索引
绘制凸包
cv2.polylines(image,[hull],True,(0,255,0),2)
凸缺陷-凸包与轮廓之间的部分
convexityDefects = cv2.convexityDefects(contour,convexhull)
convexityDefects 凸缺陷点集,一个数组[起点,终点,轮廓上距离凸包最远的点,最远的点到凸包的近似距离],前三个值为索引,需要到轮廓点中查找
contour 轮廓
convexhull 凸包 returnPoints的值必须是False
检测轮廓是否是凸形
retval = cv2.isContourConvex(contour)
retval True/False 是否凸形
contour 要判断的轮廓
点到轮廓的距离,或点和多边形的关系测试
retval = cv2.pointPolygonTest(contour,pt,measureDist)
contour 轮廓
pt 待判定的点
measureDist 判定的方式:True计算点到轮廓的距离,点在轮廓的外部返回负值,在轮廓上返回0,在内部,返回正数, False只返回-1,0,1中的一个值
计算形状场景距离-构造距离提取算子
retval = cv2.createShapeContextDistanceExtractor([,nAngularBins[,nRadialBins[,innerRadius[,outerRadus[,iterations[,comparer[,transformer]]]]]]])
nAngularBins 角容器的数量
nRadialBins 径向容器的数量
innerRadius 内半径’
outerRadus 外半径
iterations 迭代次数
comparer 直方图代价提取算子
transformer 形状变换参数
计算不同形状场景距离
retval = cv2.createShapeContextDistanceExtractor.computeDistance(contour1,contour2)
contour1,contour2 是不同的轮廓
计算Hausdorff距离-构造距离提取算子
retval = cv2.createHausdorffDistanceExtractor([,distanceFlag[,rankProp]])
distanceFlag 距离标记
rankProp 比例值0~1之间
轮廓的特征值
宽高比 = 宽度/高度
Extend = 轮廓面积(对象面积)/矩形边界面积
Solidity = 轮廓面积(对象面积)/凸包面积
Equivalent Diameter等效直径 = Sqrt(4*轮廓面积/PI)
方向 = (x,y),(MA,ma),angle = cv2.fitEllipse(cnt) 利用椭圆方向
获取掩模
参见cv2.drawContours绘制轮廓将参数thickness设为-1
使用Numpy函数获取轮廓像素点
使用numpy.nonzero()找出数组内非0元素的位置,返回值是将行列分别显示
再使用numpy.transpose()处理上述结果,得到这些点的(x,y)坐标
使用OpenCV函数获取轮廓点
idx = cv2.findNonZero(src)
idx 非0元素的索引位置,每个元素对应的是(列号,行号)格式
src 要查找的非零元素的图像
最大值最小值及其位置
min_val,max_val,min_loc,max_loc = cv2.minMaxLoc(imgray,mask=mask)
min_val,max_val 最小值,最大值
min_loc,max_loc 最小值,最大值的位置
imgray 单通道图像,灰度图像
mask 掩模
平均颜色及平均灰度
mean_val = cv2.mean(im,mask = mask) 能够计算各个通道的均值
im 原图像
mask 掩模
极点
leftmost = tuple(cnt[cnt[:,:,0].argmin()][0]) 最左端点
rightmost = tuple(cnt[cnt[:,:,0].argmax()][0]) 最右端点
topmost = tuple(cnt[cnt[:,:,1].argmin()][0]) 最上端点
bottommost = tuple(cnt[cnt[:,:,1].argmax()][0]) 最下端点
绘制直方图-matplotlib.pyplot.hist()
matplotlib.pyplot.hist(x,BINS)
x 数据源
BINS BINS值,灰度级的分组情况
二维数组降为一维数组
b = a.ravel()
绘制直方图-cv2.calcHist
hist = cv2.calcHist(images,channels,mask,histSize,ranges,accumulate)
hist 统计直方图,一维数组
images 原始图像,需用[]括起来
channels 通道编号,需用[]括起来,单通道灰度图为0,彩色图0,1,2,对应B,G,R
mask 掩模图像
histSize BINS的值,需用[]括起来
ranges 像素值的范围,如8位灰度图像素值[0,255]
accumulate 默认False,累计/叠加标识,为True时直方图开始计算时不清零,用于一组图像计算,实时更新直方图,从多个对象中计算单个直方图,一般不用设置
matplotlib.pyplot.plot 直方图绘图
plt.plot(x,y,color=’r’) 省略x轴时默认生成与y长度一致的自然序数
直方图均衡化,综合考虑了统计概率和HVS的均衡化
dst = cv2.equalizeHist(src)
src 8位单通道原始图像
matplotlib.pyplot.subplot 向当前窗口添加一个子窗口对象
matplotlib.pyplot.subplot(nrows,ncols,index)
matplotlib.pyplot.imshow 显示窗口,注意openCV的通道顺序BGR
matplotlib.pyplot.imshow(X, cmap=None)
X 图像信息
cmap 色彩空间 默认null RGB(A)色彩空间
matplotlib.pyplot.figure 构建窗口
matplotlib.pyplot.figure(‘text’)
matplotlib.pyplot.axis 关闭/显示坐标轴
matplotlib.pyplot.axis(‘off’)
numpy实现傳里叶变换
retval = numpy.fft.fft2(原始灰度图像)
retval 复数数组的频谱信息
零频率成分移动到频域图像中心位置
retval = numpy.fft.fftshift(原始频谱)
频谱信息转换到[0,255]的灰度空间图
像素新值 = 20*np.log(np.abs(频谱信息值))
零频率成分移动到频域图像中心位置的反向操作,移回原位
retval = numpy.fft.ifftshift(原始频谱)
numpy实现逆傳里叶变换
retval = numpy.fft.ifft2(频域数据)
retval 复数数组的空域信息
空域信息转换到[0,255]的灰度空间图
像素新值 = np.abs(空域信息)
高通滤波,增加图中尖锐细节,保留边缘信息,低通滤波使图像变模糊
f = np.fft.fft2(img)
fshift = np.fft.fftshift(f)
rows, cols = img.shape
crow, ccol = int(rows/2), int(cols/2)
fshift[crow-30:crow+30, ccol-30:ccol+30] = 0
ishift2 = np.fft.ifftshift(fshift)
iimg2 = np.fft.ifft2(ishift2)
iimg2 = np.abs(iimg2)
opencv实现傳里叶变换
rstval = cv2.dft(原始图像,转换标识)
rstval 返回结果与nupmy转换一致,但是双通道,1通道为实数部分,2通道为虚数部分,再使用numpy.fft.fftshift(rstval)移到中心位置,再计算频谱信息的幅度,然后再20*np.log(),得到频谱信息
原始图像 要先使用np.float32()转换格式
转换标识 通常为cv2.DFT_COMPLEX_OUTPUT输出一个复数阵列
计算频谱信息的幅度
rstval = cv2.magnitude(实部,虚部)
将幅度值映射为灰度空间[0,255]
20*np.log(rstval)
opencv实现逆傳里叶变换
rstval = cv2.dft(频域数据)
频域数据 如果先前移动了零频率分量,在使用前要先ifftshift移回原位置
低通滤波
dft = cv2.dft(np.float32(img), flags=cv2.DFT_COMPLEX_OUTPUT)
dftshift = np.fft.fftshift(dft)
rows, cols = img.shape
crow, ccol = int(rows/2), int(cols/2)
mask = np.zeros((rows, cols, 2), np.uint8)
.# 两个通道,与频域图像匹配
mask[crow-30:crow+30, ccol-30:ccol+30] = 1
fshift = dftshift * mask
ishift = np.fft.ifftshift(fshift)
iimg2 = cv2.idft(ishift)
iimg2 = cv2.magnitude(iimg2[:, :, 0], iimg2[:, :, 1])
模版匹配
rstval = cv2.matchtemplate(image, templ, method[,mask])
rstval 比较结果集,单通道32位浮点型,原始图大小WH,模版大小wh,返回值大小(W-w+1)*(H-h+1),前两种返回0最匹配,其它值越大越匹配,查极值
image 原始图像8位或32位的浮点型图像
templ 模版图像,小于或等原始图像,与它具有相同的类型
method 匹配方法cv2.TM_SQDIFF/TM_SQDIFF_NORMED/TM_CCPRR/TM_CCORR_NORMED/TM_CCOEFF/TM_CCOEFF_NORMED
mask 模版图像掩模,和ermpl具有相同的大小和类型,通常默认值即可,仅支持TM_SQDIFF/TM_CCORR_NORMED
查找最值(极值)与所在的位置
minVal,maxVal,minLoc,maxLoc = cv2.minMaxLoc(src[,mask])
minVal,maxVal,minLoc,maxLoc 极值与位置,可以为NULL
src 单通道数据
mask 掩模的子集
*取模版图像的宽高时语句
th,tw = template.shape[::]
tw,th = template.shape[::-1]
多模版匹配
loc = np.where(res >= threshold) 能够获取模版匹配位置的集合
threshold 预设阀值
遍历位置
for i in zip(模版匹配索引集合)
行列位置互换
loc[::-1]
标记各个匹配位置
for pt in zip(loc[::-1])
cv2.rectangle(img,pt,(pt[0]+w, pt[1]+h), 255, 1)
霍夫直线变换
lines = cv2.HoughLines(image,rho,theta,threshold)
lines 中每个元素都是一对浮点数,表示检测到的直线参数即(r,0)
image 源图像8位单通道的二值图像
rho 以像素为单位的距离r的精度,一般为1
theta 角度0的精度,一般pi/180,表示搜索所有可能的角度
threshold 阀值,越小判定出的直线越多
概率霍夫直线变换
lines = cv2.HoughLinesP(image,rho,theta,threshold,minLineLength,maxLineGap)
lines 中每个元素都是一对浮点数,表示检测到的直线参数即(r,0)
image 源图像8位单通道的二值图像
rho 以像素为单位的距离r的精度,一般为1
theta 角度0的精度,一般pi/180,表示搜索所有可能的角度
threshold 阀值,越小判定出的直线越多
minLineLength 接受直线的最小长度,默认0
maxLineGap 接受共线线段之间的最小间隔,即一条线段两点的最大间隔
霍夫圆环变换,在使用前先进行平滑操作,减少噪声,避免误判
circles = cv2.HoughCircles(image,method,dp,minDist,param1,param2,minRadius,maxRadius)
image 源图像8位单通道的灰度图像
method 检测方法,目前只有HOUGH_GRADIENT两轮检测
dp 累计器分辨率,分隔比率,为1表示输入图像与累加器有相同的分辨率
minDist 圆心间的最小间距,被作为阀值使用
param1 默认100,对应Canny边缘检测器的高阀值(低阀值是高阀值的1/2)
param2 圆心位置必须收到的投票数,值越大,检测到的圆越少,默认100
minRadius圆半径的最小值,默认为0,参数不起作用
maxRadius 圆半径的最大值,默认为0,参数不起作用
分水岭算法cv2.watershed(),形态学函数(各个子图没有连接时),距离变换函数cv2.distanceTransform(),cv2.connectedComponents()
形态学函数用于简单的图像
未知区域UN = (图像O-确定背景B) – 确定前景
(图像O-确定背景B) 可用图像进行形态学膨胀操作得到
分水岭算法图像分隔
markers = cv2.watershed(image,markers)
image 8位三通道图像,在处理前先用正数大致勾画出图像期望分隔的区域
markers 32位单通道的标注结果,和image具有相等大小,-1为边界
具体使用
# 转为灰度图
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# OTSU阈值处理
ret, thresh = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)
# 开运算,对原始图像去噪
kernel = np.ones((3, 3), np.uint8)
opening = cv2.morphologyEx(thresh, cv2.MORPH_OPEN, kernel=kernel, iterations=2)
# 对过膨胀,得到确定背景B
sure_bg = cv2.dilate(opening, kernel, iterations=3)
# 利用距离变换,并对其阈值处理,得到确定前景F
dist_transform = cv2.distanceTransform(opening, cv2.DIST_L2, 5)
# 确定前景F 阈值处理
ret, sure_fg = cv2.threshold(dist_transform, 0.7*dist_transform.max(), 255, 0)
sure_fg = np.uint8(sure_fg)
# 计算未知区域UN
unknown = cv2.subtract(sure_bg, sure_fg)
# 对原图像O进行标注
ret, markers2 = cv2.connectedComponents(sure_fg)
# 对标注结果进行修正,适应分水岭算法,将未知区域标注为0
markers2 = markers2 + 1
markers2[unknown == 255] = 0
# 使用分水岭函数进行图像的分割
markers3 = cv2.watershed(img2, markers2)
# 显示彩色分割标记 -1表示边界
img2[markers3 == -1] = [0, 255, 0]
判断摄像头是否初始化成功
retval = cv2.VideoCapture.isOpened()
retval True成功 False失败
初始化失败后打开摄像头
retval = cv2.VideoCapture.open(摄像头ID或文件名)
捕获帧
retval, img = cap.read()
img 捕获到的帧,没有为空
retval True成功 False失败
关闭摄像头
None= cv2.VideoCapture.cap.release()
摄像头属性获取
retval = cv2.VideoCapture.cap.get(propid)
propid 对象属性 cv2.CAP_PROP_FRAME_WIDTH 宽3 cv2.CAP_PROP_FRAME_HEIGHT 高4 FYI P385
摄像头属性设置
retval = cv2.VideoCapture.cap.get(propid, value)
捕获多个摄像头数据
retval = cv2.VideoCapture.grab() 指向下一帧
retval True False 是否成功指向下一帧
下一步
retval, image = cv2.VideoCapture.retrieve() 解码并返回一帧
retval True False 是否成功
image 返回的视频帧,失败为空图像
VideoWriter 保存视频文件,修改视频属性,类型转换等
filename 输出目标视频的文件路径和文件名
fourcc 视频编码/解码类型 -1为弹窗口选择
fps 帧速率
frameSize 每帧的长和宽
isColor 是否彩色图像
写入下一帧视频
None = cv2.VideoWriter(image)
释放
None = cv2.VideoWriter.release()
out.release()
指定视频编/解码格式
cv2.VideoWriter_fourcc(4个字符参数) ‘I’,’4′,’2′,’0′ 未压缩YUV的.avi ‘X’,’V’,’T’,’D’ MPEG-4的.avi 更多参见www.fourcc.org
img 载体图像,画布,画板
color 绘制颜色,注意是BGR,灰度图像只能传入灰度值
thickness 线条粗细,-1 表示填充为实心
lineType 张条类型,默认是8连接类型
shift 数据精度,一般不用设置
绘制矩形
img = cv2.rectangle(img,pt1,pt2,color[,thickness[,lineType]])
绘制圆形
img = cv2.circle(img,center,radius,color[,thickness[,lineType]])
center 圆心
radius 半径
绘制椭圆
img = cv2.ellipse(img,center,axes,angle,startAngle,endAngle,color[,thickness[,lineType]])
center 圆心
axes 轴的长度
angle 偏转的角度
startAngle 圆弧起始角的角度
endAngle 圆弧终结角的角度
绘制多边形
img = cv2.polylines(img,pts,isClosed,color[,thickness[,lineType[,shift]]])
pts 多边形的各个顶点 数组类型为numpy.int32
isClosed 闭合标记
图形上绘制文字
img = cv2.putText(img,text,org,fontFace,fontScale,color[,thickness[,lineType[,bottomLeftOrigin]]])
text 绘制的文字
org 绘制的文字位置,以文字的左下角为起点
fontFace 字体类型,cv2.FONT_HESRESHEY_SIMPLEX …
fontScale 字体大小
bottomLeftOrigin 控制文字的方向 默认False,True时垂直镜像的效果
鼠标交互
定义响应函数
def OnMouseAction(event,x,y,flags,param):
OnMouseAction 响应函数名,可自定
event 鼠标事件
x,y 鼠标触发事件时,鼠标在窗口中的坐标
flags 鼠标的拖拽事件,及键盘鼠标的联合事件
param 标识所响应的事件函数
函数与窗口绑定
cv2.setMouseCallback(winname,onMouse)
winname 绑定的窗口名
onMouse 响应的函数名
查看opencv所支持的鼠标事件
events = [i for in dir(cv2) if ‘EVENT’ in i]
print(events)
创建窗口
cv2.namedWindows(‘name’)
获取滚动条的值
retval = getTrackbarPos(trackbarname,winname)
当作开关使用时,滚动条只有两种值0,1
knn = cv2.ml.KNearest_create()
knn.train(trainData,cv2.ml.ROW_SAMPLE,tdLable)
ret,results,neighbours,dist = knn.findNearest(dst,k)
ret
results 可以判定的类型
neighbours 距离当前最近的k个邻居
dist k个最近邻居的距离
sk-learn库,LIBSVM库…
生成用于后续训练的空分类器模型
svm = cv2.ml.SVM_create()
训练结果 = svm.train(训练数据,训练数据排列格式,训练数据的标签)
训练数据排列格式 cv2.ml.ROW_SAMPLE 按行 cv2.ml.COL_SAMPLE 按列
(返回值,返回结果) = svm.predict(测试数据)
参数调整:setType()设置类别 setKernel()设置核类型 setC()设置支持向量机的参数C(惩罚系数,对误差的宽容度,默认0)
retval,bestLabels,centers = cv2.kmeans(data,K,bestLables,criteria,attempts,flags)
retval 距离值,返回每个点到相应中心距离的平方和
bestLabels 各个数据点的最终分类标签(索引)
centers 每个分类的中心点数据
data 待处理的数据集合,np.float32类型,每个特征单独一列中
K 要分出簇的个数,常见2,表示2分类
bestLables 各个数据点的最终分类标签(索引),实际中设为None
criteria 算法迭代的终止条件,达到最大循环数目和指定精度阀值时终止,由3个参数构成type,max_iter,eps
type: cv2.TEEM_CRITERIA_EPS 精度满足 MAX_ITER 迭代次数超过阀值max_iter时停止 _EPS+MAX_ITER两个任意一个满足停止
max_iter 最大迭代次数
eps 精确度的阀值
attempts 使用不用的初始值多次(attempts次)偿试
flags 选择初始中心点的方法,主要有3种cv2.KMEANS_RANDOM_CENTERS 随机 cv2.KMEANS_PP_CENTERS基于中心算法 cv2.KMEANS_USE_INITIAL_LABELS 使用用户输入的数据作为第一次分类的中心点,需要多次偿试时后续使用随机或半随机值作为第一次分类中心点
训练级联分类器
在opencv根目录\bulid\x86\vc12\bin中的opencv_createsamples.exe opencv_traincascade.exe
自带的分类器
在opencv源文件的data文件夹下三个子文件夹
加载级联分类器
在anaconda使用pip安装opencv无法直接获得分类器的xml文件,可在opencv安装目录\data或网上下载相应的xml文件
级联人脸检测使用
objects = cv2.CascadeClassifier.detectMultiScale(image[,scaleFactor[,minNeighbors[,flags[,minSize[,maxSize]]]]])
objects 目标对像的矩形框向量组
image 待检测图像,通常灰度图像
scaleFactor 在前后前后两次相继的扫描中搜索窗口的缩放比例
minNeighbors 构成检测目标的相邻矩形的最小个数,默认为3,提高检测的准确率可设得更大,但可能让一些人脸无法被检测到
flags 能常补省略,在低版1.X时,可能被设置为CV_HAAR_DO_CANNY_RUNNING 表示用canny边缘检测器来拒绝一些区域
minSize 目标的最小尺寸,小于会补忽略
maxSize 目标的最大尺寸,大于会补忽略
LBPH 局部二值模式直方图
1生成LBPH识别器实例模型
retval = cv2.face.LBPHFaceRecognizer_create([,radius[,neighbors[,grid_x[,grid_y[,thershold]]]]])
radius 半径值,默认为1
neighbors 领域点的个数,默认8
grid_x 特征图划分为一个个单元格时,每个单元格在水平方向上的像素个数,默认8
grid_y 特征图划分为一个个单元格时,每个单元格在垂直方向上的像素个数,默认8
thershold 在预测时所使用的阀值,大于此阀值就认为没有识别到任何目标
2 对每个参考图计算LBPH,得到一向量,每个人的脸都是整个向量的一个点,完成训练
None = cv2.face_FaceRecognizer.train(src, labels)
src 训练图像,用来学习的人脸图像
labels 人脸图像所对应的标签
3检测识别
label, confidence = cv2.face_FaceRecognizer.predict(src)
label 返回的识别结果标签
confidence 返回的置信度评分,0完全匹配,小于50可以接受,大于80差别较大
src 需要识别的图像
EigenFishfaces特征脸,使用成分分析PCA,操作过程中会损失许多特征信息
1生成特征脸识别器实例模型
retval = cv2.face.EigenFaceRecognizer_create([,num_components[,threshold]])
num_components PCA中要保留的分量个数,一般80个就够了
threshold 人脸识别的阀值
2对每个参考图计算,得到一向量,每个人的脸都是整个向量的一个点,完成训练
None = cv2.face_EigenFaceRecognizer.train(src,labels)
src 训练图像,用来学习的人脸图像
labels 人脸图像所对应的标签
3检测识别
label, confidence = cv2.face_EigenFaceRecognizer.predict(src)
label 返回的识别结果标签
confidence 返回的置信度评分,0完全匹配,小于5000可以认为是可靠的,最大值20000
src 需要识别的图像
fisherfaces 线性判断分析LDA
1生成识别器实例模型
retval = cv2.face.FisherFaceRecognizer_create([,num_components[,threshold]])
num_components 线性分析时要保留的分量个数,可设为0,函数自动设置
threshold 识别的阀值,如果最近的距离比设定的阀值还要大,函数返回-1
2对每个参考图计算,得到一向量,每个人的脸都是整个向量的一个点,完成训练
None = cv2.face_FisherFaceRecognizer.train(src,labels)
src 训练图像,用来学习的人脸图像
labels 人脸图像所对应的标签
CAS-PEAL
1040位99594幅人脸图像,开放了子集 CAS-PEAL_R1 1040人的30900幅图像
AT&T Facedatabase
即以前的ORL,40个人400幅
Yale Facedatabase A
耶鲁人脸数据库,15*11
Extend Yale Facedatabase B
扩展耶鲁人脸数据库B 28964 16128张
color FERET Database
1564组,共14126张,由1199个不同拍摄对像重复拍摄,最广泛之一
人脸数据库整理网站
opencv推荐 http://face-rec.org/database
ENV TZ 'Asia/Shanghai'
RUN ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime && echo 'Asia/Shanghai' >/etc/timezone && apt-get update && apt-get install -y tzdata
C++
1. brew
brew install homebrew/science/opencv
#若要安装opencv3,如下,可同时存在2与3
brew install homebrew/science/opencv3
or
cd “$(brew –repo)”
git remote set-url origin https://mirrors.tuna.tsinghua.edu.cn/git/homebrew/brew.git
cd “$(brew –repo)/Library/Taps/homebrew/homebrew-core”
git remote set-url origin https://mirrors.tuna.tsinghua.edu.cn/git/homebrew/homebrew-core.git
cd
brew update
brew install opencv
CLion项目中的CMakeLists.txt
cmake_minimum_required(VERSION 3.9)
project(untitled1)
set(CMAKE_CXX_STANDARD 11)
#find_library(OpenCV)
find_package(OpenCV)
include_directories(${OpenCV_INCLUDE_DIRS})
add_executable(untitled1 main.cpp)
target_link_libraries(untitled1 ${OpenCV_LIBS})
如果出现一些cmake莫名其妙的错误,可以进入Tools | CMake | Reset Cache and Reload Project清空一下CMake缓存。
选中“WITH_OPENGL”、“WITH_QT”,将“WITH_IPP”取消。然后再次点【Configure】
1. 源码 https://opencv.org/releases/
在Download/opencv-3.4.2/创建build文件夹用来存编译后文件
cmake.org/download/
打开CMake,填好OpenCV路径和build的路径->configure->Done->等->Generate
打开终端,用cd命令进入build文件夹目录,然后输入命令make
然后,等它编译到100%,然后输入命令 sudo make install
编译命令为:g++ Cpp_Opencv.cpp -o Cpp_Opencv `pkg-config --cflags --libs opencv`
或者直接将链接库列出来:g++ Cpp_Opencv.cpp -L/usr/local/lib/ -lopencv_highgui.3.4.2 -lopencv_core.3.4.2 -lopencv_imgcodecs
python
pip安装
https://pypi.org/project/opencv-python/
opencv_python-4.3.0.36-cp37-cp37m-macosx_10_9_x86_64.whl
pip安装opencv无法在pycharm的anconda环境找到扩展包解决方案
不要直接pip install,进入D:\anaconda3\Scripts
将pip.exe和pip-script.py修改为condapip.exe和condapip-script.py(不加conda加别的也行,只为了和系统pip区分开)
condapip install opencv_python-4.3.0.36-cp37-cp37m-macosx_10_9_x86_64.whl
之后刷新pycharm interpretor或者重启一下,就可以成功在pycharm anaconda环境下import cv2了。
a. Packages for standard desktop environments (Windows, macOS, almost any GNU/Linux distribution)
run pip install opencv-python if you need only main modules
run pip install opencv-contrib-python if you need both main and contrib modules (check extra modules listing from OpenCV documentation)
b. Packages for server (headless) environments
These packages do not contain any GUI functionality. They are smaller and suitable for more restricted environments.
run pip install opencv-python-headless if you need only main modules
run pip install opencv-contrib-python-headless if you need both main and contrib modules (check extra modules listing from OpenCV documentation)
Import the package:
import cv2
conda install –channel https://conda.anaconda.org/menpo opencv3
conda install -c menpo opencv3
](https://pic.ikafan.com/imgp/L3Byb3h5L2h0dHBzL2ZpbGVzLmpiNTEubmV0L2ZpbGVfaW1hZ2VzL2FydGljbGUvMjAxOTAzLzIwMTkzMjI5NTcyOTIxMy5qcGcmIzA2MzsyMDE5MjIyOTU3NDg=.jpg)





SDL官网
http://www.libsdl.org/
下载:
http://www.libsdl.org/download-2.0.php
生成Makefile
configure --prefix=/usr/local/sdl
安装
sudo make -j 8 && make install
使用
添加头文件 #include<SDL.h>
初始化SDL SDL_Init()
退出SDL SDL_Quit()
SDL_CreateWindow()/SDL_DestoryWindow()
SDL_CreateRender()
clang -g -o xxsdl xxxsdl.c `pkg-config --cflags --libs sdl2`
是一个跨平台的多媒体框架
windows,macOS下载
https://ffmpeg.zeranoe.com/builds/
linux
http://ffmpeg.org/releases/
查看文件信息工具
mediaInfo
tar -jxvf ffmpeg-3.4.1.tar.bz2
cd ffmpeg-3.4.1
安装yasm ----yum install yasm
./configure --enabled-shared --prefix=/usr/local/ffmpeg
安装:make && make install
修改文件/etc/ld.so.conf 中增加/usr/local/ffmpeg/lib.
使其生效:ldconfig
加入环境变量:vi /etc/profile
最后一行:export FFMPEG_HOME=/usr/local/ffmpeg
export PATH=$FFMPEG_HOME/bin:$PATH
使环境变量生效:source /etc/profile
源码下载
git clone https://git.ffmpeg.org/ffmpeg.git
按需配制模块
./configure –help | more
安装yasm的汇编编译器
yasm:http://yasm.tortall.net/Download.html
sudo apt-get install yasm
Mac 平台:
./configure –prefix=/usr/local/ffmpeg
–enable-gpl
–enable-nonfree
–enable-libfdk-aac
–enable-libx264
–enable-libx265
–enable-filter=delogo
–enable-debug
–disable-optimizations
–enable-libspeex
–enable-videotoolbox
–enable-shared
–enable-pthreads
–enable-version3
–enable-hardcoded-tables
–cc=clang
–host-cflags=
–host-ldflags=
Linux平台
./configure –prefix=/usr/local/ffmpeg \
–enable-gpl \
–enable-nonfree \
–enable-libfdk-aac \
–enable-libx264 \
–enable-libx265 \
–enable-filter=delogo \
–enable-debug \
–disable-optimizations \
–enable-libspeex \
–enable-shared \
–enable-pthreads
Windows平台
./configure –prefix=/usr/local/ffmpeg
–enable-gpl
–enable-nonfree
–enable-libfdk-aac
–enable-libx264
–enable-libx265
–enable-filter=delogo
–enable-debug
–disable-optimizations
–enable-libspeex
–enable-static
编译安装
sudo make && make install
执行
/usr/local/ffmpeg/bin/ffmpeg
为方便执行可加入环境变量~/.bash_profile
export PATH=$PATH:/usr/local/ffmpeg/bin
可能遇到的问题
ffmpeg默认安装目录为“/usr/local/lib”,有些64位系统下软件目录则为“/usr/lib64”,编译过程中可能会出现“ffmpeg: error while loading shared libraries: libmp3lame.so.0: cannot open shared object file: No such file or directory”等类似的错误,解决办法是建立软链接或者移动库文件到相应的目录:
ln -s /usr/local/lib/libmp3lame.so.0.0.0 /usr/lib64/libmp3lame.so.0
mv /usr/local/lib/libmp3lame.so.0.0.0 /usr/lib64/libmp3lame.so.0
ERROR:libfdk_aac not found
apt install fdk-aac
http://sourceforge.net/projects/opencore-amr/?source=directory
下载fdk-aac-0.1.1.tar.gz
执行
configure
make
make install
git clone git://github.com/mstorsjo/fdk-aac
cd fdk-aac
autoreconf -i
./configure
make install
ERROR: speex not found using pkg-config
apt install pkg-config
apt-get install libspeex-dev
ERROR: libx264 not found
apt/brew/yum install x264。(注:在Linux下应该安装 libx264-dev)
ffmpeg: error while loading shared libraries: libavdevice.so.58: cannot open shared object file: No such file or directory
sudo vi /etc/ld.so.conf
在文件中添加路径:
/usr/local/ffmpeg/lib
更新环境变量:
sudo ldconfig
加入全局环境变量路径:
sudo vi /etc/profile
在文件中加入以下内容:
export PATH=”/usr/local/ffmpeg/bin:$PATH”
然后保存并运行source /etc/profile
查看下需要哪些依赖:
ldd ffmpeg
找下这些文件在哪里
find /usr -name ‘libavdevice.so.58’
FYI 《FFmpeg精讲与实战》常见问题与解答
https://www.imooc.com/article/253497
windows下安装
www.imooc.com/article/247113
基本信息查询命令
FFMPEG 可以使用下面的参数进行基本信息查询。例如,想查询一下现在使用的 FFMPEG 都支持哪些 filter,就可以用 ffmpeg -filters 来查询。详细参数说明如下:
-version 显示版本。 ffmpeg -version
-formats 显示可用的格式(包括设备)。
-demuxers 显示可用的demuxers。
-muxers 显示可用的muxers。
-devices 显示可用的设备。
-codecs 显示libavcodec已知的所有编解码器。
-decoders 显示可用的解码器。
-encoders 显示所有可用的编码器。
-bsfs 显示可用的比特流filter。
-protocols 显示可用的协议。
-filters 显示可用的libavfilter过滤器。
-pix_fmts 显示可用的像素格式。
-sample_fmts 显示可用的采样格式。
-layouts 显示channel名称和标准channel布局。
-colors 显示识别的颜色名称。
接下来介绍的是 FFMPEG 处理音视频时使用的命令格式与参数。
命令基本格式及参数
下面是 FFMPEG 的基本命令格式:
ffmpeg [global_options] {[input_file_options] -i input_url} …
{[output_file_options] output_url} …
ffmpeg 通过 -i 选项读取输任意数量的输入“文件”(可以是常规文件,管道,网络流,抓取设备等,并写入任意数量的输出“文件”。
原则上,每个输入/输出“文件”都可以包含任意数量的不同类型的视频流(视频/音频/字幕/附件/数据)。 流的数量和/或类型是由容器格式来限制。 选择从哪个输入进入到哪个输出将自动完成或使用 -map 选项。
要引用选项中的输入文件,您必须使用它们的索引(从0开始)。 例如。 第一个输入文件是0,第二个输入文件是1,等等。类似地,文件内的流被它们的索引引用。 例如。 2:3是指第三个输入文件中的第四个流。
上面就是 FFMPEG 处理音视频的常用命令,下面是一些常用参数:
主要参数
-f fmt(输入/输出) 强制输入或输出文件格式。 格式通常是自动检测输入文件,并从输出文件的文件扩展名中猜测出来,所以在大多数情况下这个选项是不需要的。
-i url(输入) 输入文件的网址
-y(全局参数) 覆盖输出文件而不询问。
-n(全局参数) 不要覆盖输出文件,如果指定的输出文件已经存在,请立即退出。
-c [:stream_specifier] codec(输入/输出,每个流) 选择一个编码器(当在输出文件之前使用)或解码器(当在输入文件之前使用时)用于一个或多个流。codec 是解码器/编码器的名称或 copy(仅输出)以指示该流不被重新编码。如:ffmpeg -i INPUT -map 0 -c:v libx264 -c:a copy OUTPUT
-codec [:stream_specifier]编解码器(输入/输出,每个流) 同 -c
-t duration(输入/输出) 当用作输入选项(在-i之前)时,限制从输入文件读取的数据的持续时间。当用作输出选项时(在输出url之前),在持续时间到达持续时间之后停止输出。
-ss位置(输入/输出) 当用作输入选项时(在-i之前),在这个输入文件中寻找位置。 请注意,在大多数格式中,不可能精确搜索,因此ffmpeg将在位置之前寻找最近的搜索点。 当转码和-accurate_seek被启用时(默认),搜索点和位置之间的这个额外的分段将被解码和丢弃。 当进行流式复制或使用-noaccurate_seek时,它将被保留。当用作输出选项(在输出url之前)时,解码但丢弃输入,直到时间戳到达位置。
-frames [:stream_specifier] framecount(output,per-stream) 停止在帧计数帧之后写入流。
-filter [:stream_specifier] filtergraph(output,per-stream) 创建由filtergraph指定的过滤器图,并使用它来过滤流。filtergraph是应用于流的filtergraph的描述,并且必须具有相同类型的流的单个输入和单个输出。在过滤器图形中,输入与标签中的标签相关联,标签中的输出与标签相关联。有关filtergraph语法的更多信息,请参阅ffmpeg-filters手册。
视频参数
-vframes num(输出) 设置要输出的视频帧的数量。对于-frames:v,这是一个过时的别名,您应该使用它。
-r [:stream_specifier] fps(输入/输出,每个流) 设置帧率(Hz值,分数或缩写)。作为输入选项,忽略存储在文件中的任何时间戳,根据速率生成新的时间戳。这与用于-framerate选项不同(它在FFmpeg的旧版本中使用的是相同的)。如果有疑问,请使用-framerate而不是输入选项-r。作为输出选项,复制或丢弃输入帧以实现恒定输出帧频fps。
-s [:stream_specifier]大小(输入/输出,每个流) 设置窗口大小。作为输入选项,这是video_size专用选项的快捷方式,由某些分帧器识别,其帧尺寸未被存储在文件中。作为输出选项,这会将缩放视频过滤器插入到相应过滤器图形的末尾。请直接使用比例过滤器将其插入到开头或其他地方。格式是’wxh’(默认 – 与源相同)。
-aspect [:stream_specifier] 宽高比(输出,每个流) 设置方面指定的视频显示宽高比。aspect可以是浮点数字符串,也可以是num:den形式的字符串,其中num和den是宽高比的分子和分母。例如“4:3”,“16:9”,“1.3333”和“1.7777”是有效的参数值。如果与-vcodec副本一起使用,则会影响存储在容器级别的宽高比,但不会影响存储在编码帧中的宽高比(如果存在)。
-vn(输出) 禁用视频录制。
-vcodec编解码器(输出) 设置视频编解码器。这是-codec:v的别名。
-vf filtergraph(输出) 创建由filtergraph指定的过滤器图,并使用它来过滤流。
音频参数
-aframes(输出) 设置要输出的音频帧的数量。这是-frames:a的一个过时的别名。
-ar [:stream_specifier] freq(输入/输出,每个流) 设置音频采样频率。对于输出流,它默认设置为相应输入流的频率。对于输入流,此选项仅适用于音频捕获设备和原始分路器,并映射到相应的分路器选件。
-ac [:stream_specifier]通道(输入/输出,每个流) 设置音频通道的数量。对于输出流,它默认设置为输入音频通道的数量。对于输入流,此选项仅适用于音频捕获设备和原始分路器,并映射到相应的分路器选件。
-an(输出) 禁用录音。
-acodec编解码器(输入/输出) 设置音频编解码器。这是-codec的别名:a。
-sample_fmt [:stream_specifier] sample_fmt(输出,每个流) 设置音频采样格式。使用-sample_fmts获取支持的样本格式列表。
-af filtergraph(输出) 创建由filtergraph指定的过滤器图,并使用它来过滤流。
了解了这些基本信息后,接下来我们看看 FFMPEG 具体都能干些什么吧。
录制
首先通过下面的命令查看一下 mac 上都有哪些设备。
ffmpeg -f avfoundation -list_devices true -i “”
录屏
ffmpeg -f avfoundation -i 1 -r 30 out.yuv
-f 指定使用 avfoundation 采集数据。
-i 指定从哪儿采集数据,它是一个文件索引号。在我的MAC上,1代表桌面(可以通过上面的命令查询设备索引号)。
-r 指定帧率。按ffmpeg官方文档说-r与-framerate作用相同,但实际测试时发现不同。-framerate 用于限制输入,而-r用于限制输出。
注意,桌面的输入对帧率没有要求,所以不用限制桌面的帧率。其实限制了也没用。
录屏+声音
ffmpeg -f avfoundation -i 1:0 -r 29.97 -c:v libx264 -crf 0 -c:a libfdk_aac -profile:a aac_he_v2 -b:a 32k out.flv
-i 1:0 冒号前面的 “1” 代表的屏幕索引号。冒号后面的”0″代表的声音索相号。
-c:v 与参数 -vcodec 一样,表示视频编码器。c 是 codec 的缩写,v 是video的缩写。
-crf 是 x264 的参数。 0 表式无损压缩。
-c:a 与参数 -acodec 一样,表示音频编码器。
-profile 是 fdk_aac 的参数。 aac_he_v2 表式使用 AAC_HE v2 压缩数据。
-b:a 指定音频码率。 b 是 bitrate的缩写, a是 audio的缩与。
录视频
ffmpeg -framerate 30 -f avfoundation -i 0 out.mp4
-framerate 限制视频的采集帧率。这个必须要根据提示要求进行设置,如果不设置就会报错。
-f 指定使用 avfoundation 采集数据。
-i 指定视频设备的索引号。
视频+音频
ffmpeg -framerate 30 -f avfoundation -i 0:0 out.mp4
录音
ffmpeg -f avfoundation -i :0 out.wav
录制音频裸数据
ffmpeg -f avfoundation -i :0 -ar 44100 -f s16le out.pcm
分解与复用
流拷贝是通过将 copy 参数提供给-codec选项来选择流的模式。它使得ffmpeg省略了指定流的解码和编码步骤,所以它只能进行多路分解和多路复用。 这对于更改容器格式或修改容器级元数据很有用。 在这种情况下,上图将简化为:

由于没有解码或编码,速度非常快,没有质量损失。 但是,由于许多因素,在某些情况下可能无法正常工作。 应用过滤器显然也是不可能的,因为过滤器处理未压缩的数据。
抽取音频流
ffmpeg -i input.mp4 -acodec copy -vn out.aac
acodec: 指定音频编码器,copy 指明只拷贝,不做编解码。
vn: v 代表视频,n 代表 no 也就是无视频的意思。
抽取视频流
ffmpeg -i input.mp4 -vcodec copy -an out.h264
vcodec: 指定视频编码器,copy 指明只拷贝,不做编解码。
an: a 代表视频,n 代表 no 也就是无音频的意思。
转格式
ffmpeg -i out.mp4 -vcodec copy -acodec copy out.flv
上面的命令表式的是音频、视频都直接 copy,只是将 mp4 的封装格式转成了flv。
音视频合并
ffmpeg -i out.h264 -i out.aac -vcodec copy -acodec copy out.mp4
处理原始数据
提取YUV数据
ffmpeg -i input.mp4 -an -c:v rawvideo -pixel_format yuv420p out.yuv
ffplay -s wxh out.yuv
-c:v rawvideo 指定将视频转成原始数据
-pixel_format yuv420p 指定转换格式为yuv420p
YUV转H264
ffmpeg -f rawvideo -pix_fmt yuv420p -s 320×240 -r 30 -i out.yuv -c:v libx264 -f rawvideo out.h264
提取PCM数据
ffmpeg -i out.mp4 -vn -ar 44100 -ac 2 -f s16le out.pcm
ffplay -ar 44100 -ac 2 -f s16le -i out.pcm
PCM转WAV
ffmpeg -f s16be -ar 8000 -ac 2 -acodec pcm_s16be -i input.raw output.wav
滤镜
在编码之前,ffmpeg可以使用libavfilter库中的过滤器处理原始音频和视频帧。 几个链式过滤器形成一个过滤器图形。 ffmpeg区分两种类型的过滤器图形:简单和复杂。
简单滤镜
简单的过滤器图是那些只有一个输入和输出,都是相同的类型。 在上面的图中,它们可以通过在解码和编码之间插入一个额外的步骤来表示:
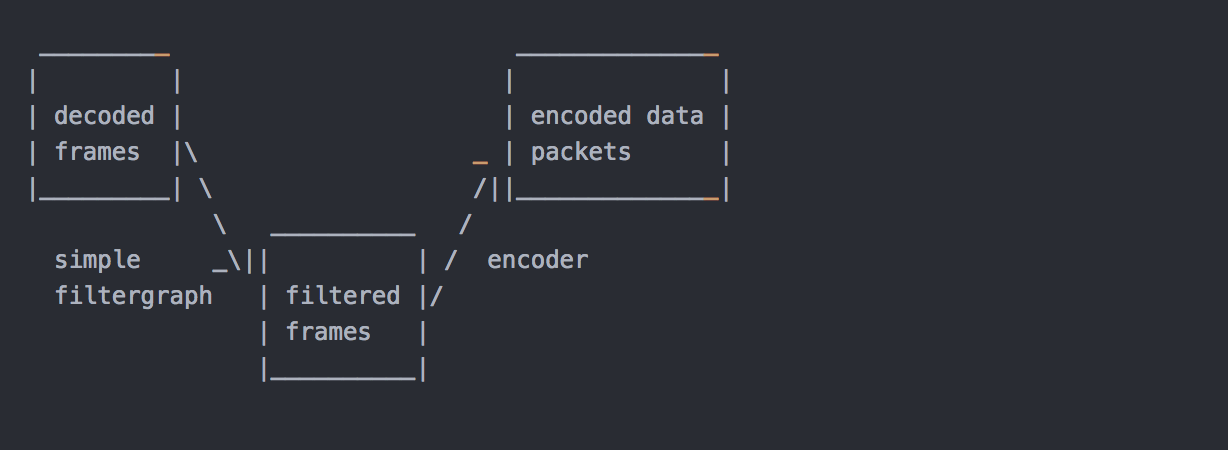
简单的filtergraphs配置了per-stream-filter选项(分别为视频和音频使用-vf和-af别名)。 一个简单的视频filtergraph可以看起来像这样的例子:
请注意,某些滤镜会更改帧属性,但不会改变帧内容。 例如。 上例中的fps过滤器会改变帧数,但不会触及帧内容。 另一个例子是setpts过滤器,它只设置时间戳,否则不改变帧。
复杂滤镜
复杂的过滤器图是那些不能简单描述为应用于一个流的线性处理链的过滤器图。 例如,当图形有多个输入和/或输出,或者当输出流类型与输入不同时,就是这种情况。 他们可以用下图来表示:
复杂的过滤器图使用-filter_complex选项进行配置。 请注意,此选项是全局性的,因为复杂的过滤器图形本质上不能与单个流或文件明确关联。
-lavfi选项等同于-filter_complex。
一个复杂的过滤器图的一个简单的例子是覆盖过滤器,它有两个视频输入和一个视频输出,包含一个视频叠加在另一个上面。 它的音频对应是amix滤波器。
添加水印
ffmpeg -i out.mp4 -vf “movie=logo.png,scale=64:48[watermask];[in][watermask] overlay=30:10 [out]” water.mp4
-vf中的 movie 指定logo位置。scale 指定 logo 大小。overlay 指定 logo 摆放的位置。
删除水印
先通过 ffplay 找到要删除 LOGO 的位置
ffplay -i test.flv -vf delogo=x=806:y=20:w=70:h=80:show=1
使用 delogo 滤镜删除 LOGO
ffmpeg -i test.flv -vf delogo=x=806:y=20:w=70:h=80 output.flv
视频缩小一倍
ffmpeg -i out.mp4 -vf scale=iw/2:-1 scale.mp4
-vf scale 指定使用简单过滤器 scale,iw/2:-1 中的 iw 指定按整型取视频的宽度。 -1 表示高度随宽度一起变化。
视频裁剪
ffmpeg -i VR.mov -vf crop=in_w-200:in_h-200 -c:v libx264 -c:a copy -video_size 1280×720 vr_new.mp4
crop 格式:crop=out_w:out_h❌y
out_w: 输出的宽度。可以使用 in_w 表式输入视频的宽度。
out_h: 输出的高度。可以使用 in_h 表式输入视频的高度。
x : X坐标
y : Y坐标
如果 x和y 设置为 0,说明从左上角开始裁剪。如果不写是从中心点裁剪。
倍速播放
ffmpeg -i out.mp4 -filter_complex “[0:v]setpts=0.5PTS[v];[0:a]atempo=2.0[a]” -map “[v]” -map “[a]” speed2.0.mp4
-filter_complex 复杂滤镜,[0:v]表示第一个(文件索引号是0)文件的视频作为输入。setpts=0.5PTS表示每帧视频的pts时间戳都乘0.5 ,也就是差少一半。[v]表示输出的别名。音频同理就不详述了。
map 可用于处理复杂输出,如可以将指定的多路流输出到一个输出文件,也可以指定输出到多个文件。”[v]” 复杂滤镜输出的别名作为输出文件的一路流。上面 map的用法是将复杂滤镜输出的视频和音频输出到指定文件中。
对称视频
ffmpeg -i out.mp4 -filter_complex “[0:v]pad=w=2*iw[a];[0:v]hflip[b];[a][b]overlay=x=w” duicheng.mp4
hflip 水平翻转
如果要修改为垂直翻转可以用vflip。
画中画
ffmpeg -i out.mp4 -i out1.mp4 -filter_complex “[1:v]scale=w=176:h=144:force_original_aspect_ratio=decrease[ckout];[0:v][ckout]overlay=x=W-w-10:y=0[out]” -map “[out]” -movflags faststart new.mp4
录制画中画
ffmpeg -f avfoundation -i “1” -framerate 30 -f avfoundation -i “0:0”
-r 30 -c:v libx264 -preset ultrafast
-c:a libfdk_aac -profile:a aac_he_v2 -ar 44100 -ac 2
-filter_complex “[1:v]scale=w=176:h=144:force_original_aspect_ratio=decrease[a];[0:v][a]overlay=x=W-w-10:y=0[out]”
-map “[out]” -movflags faststart -map 1:a b.mp4
多路视频拼接
ffmpeg -f avfoundation -i “1” -framerate 30 -f avfoundation -i “0:0” -r 30 -c:v libx264 -preset ultrafast -c:a libfdk_aac -profile:a aac_he_v2 -ar 44100 -ac 2 -filter_complex “[0:v]scale=320:240[a];[a]pad=640:240[b];[b][1:v]overlay=320:0[out]” -map “[out]” -movflags faststart -map 1:a c.mp4
音视频的拼接与裁剪
裁剪
ffmpeg -i out.mp4 -ss 00:00:00 -t 10 out1.mp4
-ss 指定裁剪的开始时间,精确到秒
-t 被裁剪后的时长。
合并
首先创建一个 inputs.txt 文件,文件内容如下:
file ‘1.flv’
file ‘2.flv’
file ‘3.flv’
然后执行下面的命令:
ffmpeg -f concat -i inputs.txt -c copy output.flv
hls切片
ffmpeg -i out.mp4 -c:v libx264 -c:a libfdk_aac -strict -2 -f hls out.m3u8
-strict -2 指明音频使有AAC。
-f hls 转成 m3u8 格式。
视频图片互转
视频转JPEG
ffmpeg -i test.flv -r 1 -f image2 image-%3d.jpeg
视频转gif
ffmpeg -i out.mp4 -ss 00:00:00 -t 10 out.gif
图片转视频
ffmpeg -f image2 -i image-%3d.jpeg images.mp4
直播相关
推流
ffmpeg -re -i out.mp4 -c copy -f flv rtmp://server/live/streamName
拉流保存
ffmpeg -i rtmp://server/live/streamName -c copy dump.flv
转流
ffmpeg -i rtmp://server/live/originalStream -c:a copy -c:v copy -f flv rtmp://server/live/h264Stream
实时推流
ffmpeg -framerate 15 -f avfoundation -i “1” -s 1280×720 -c:v libx264 -f flv rtmp://localhost:1935/live/room
ffplay
播放YUV 数据
ffplay -pix_fmt nv12 -s 192×144 1.yuv
播放YUV中的 Y平面
ffplay -pix_fmt nv21 -s 640×480 -vf extractplanes=‘y’ 1.yuv
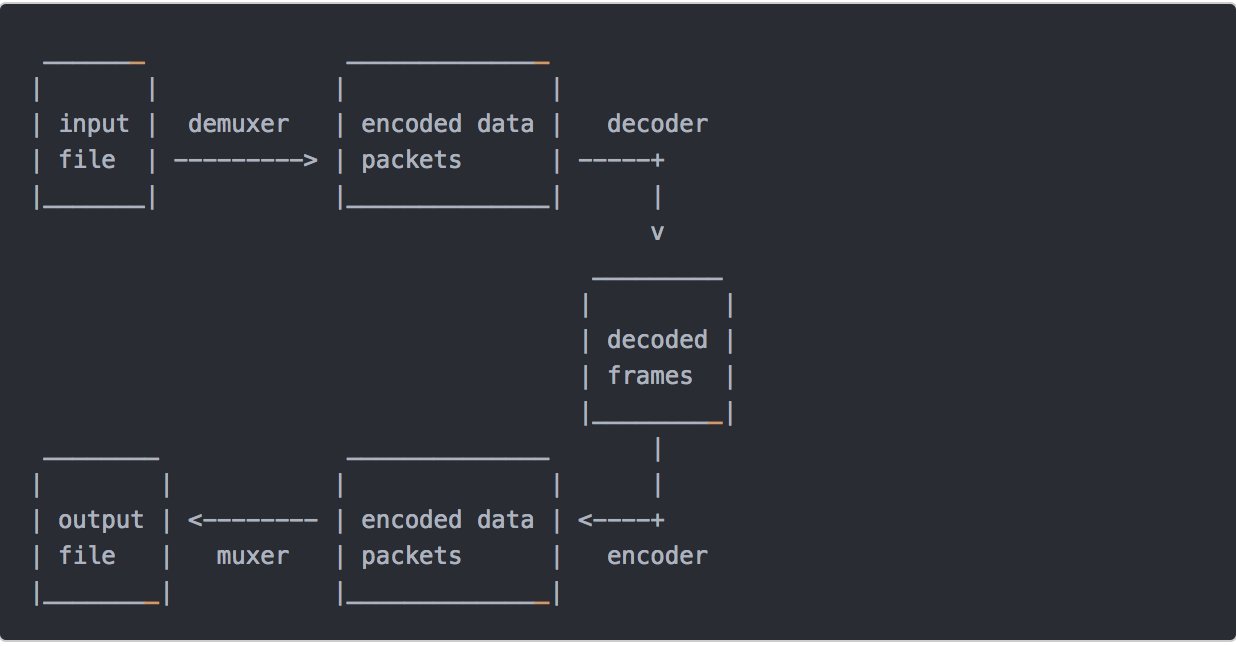
处理流程
输入文件->demuxer->编码数据包->decoder->解码后数据帧->encoder->编码数据包->muxer->输出文件
https://openvidu.io/
1) 克隆教程:
git clone https://github.com/OpenVidu/openvidu-tutorials.git
2) 您需要在开发计算机中安装http Web server 才能执行本教程。 如果安装了node.js,则可以使用 http-server 来提供应用程序文件。 通过如下命令安装:
npm install -g http-server
3) 运行教程:
openssl req -newkey rsa:2048 -new -nodes -x509 -days 3650 -keyout key.pem -out cert.pem
http-server -S -C cert.pem openvidu-tutorials/openvidu-hello-world/web
4) openvidu-server 和 Kurento Media Server 必须在您开发计算机中启动并运行。 最简单的方法是使用Docker容器运行(也可以参考前一篇文字的安装方式):
docker run -p 4443:4443 –rm -e openvidu.secret=MY_SECRET openvidu/openvidu-server-kms
5)一旦服务器运行,我们可以使用浏览器打开https://localhost:8080来测试应用程序。 第一次使用docker容器并加入视频通话时,会提示您接受openvidu-server的自签名证书。
如果您使用的是Windows,请阅读此常见问题解答以正确运行本教程
要了解使用OpenVidu开发的一些技巧,请查看此常见问题解答
二、源码解析
这个应用程序非常简单。 它只有4个文件:
openvidu-browser-VERSION.js:openvidu-browser 库文件, 您不必操纵此文件。app.js:示例应用程序主JavaScritp文件,它使用了 openvidu-browser-VERSION.js。style.css:一些用于样式index.html的CSS类。index.html:表单的HTML代码,用于连接视频通话。 它链接到两个JavaScript文件:
<script src="openvidu-browser-VERSION.js"></script>
<scriptsrc="app.js"></script>
让我们看看在 app.js 中如何使用openvidu-browser-VERSION.js:
第一行声明了代码中不同会话点所需的变量
var OV;
var session;
OV 是我们的 OpenVidu 对象(libray的入口点)。 session是我们视频通话的连接。 作为joinSession() 方法中的第一句,将识别我们视频调用的变量进行初始化,该视频调用从HTML输入中检索值。
var mySessionId = document.getElementById(“sessionId”).value;
初始化 new session 及其 event
OV = new OpenVidu();
session = OV.initSession();
session.on(‘streamCreated’, function (event) {
session.subscribe(event.stream, ‘subscriber’);
});
正如您在代码中看到的,该过程非常简单:获取OpenVidu对象并使用它初始化Session对象。
然后,您可以订阅会话所需的所有事件。 在这种情况下,我们只想订阅会话中正在创建的每个流:在streamCreated上,我们订阅特定的流,在event.stream属性中可用。
您可以查看参考文档中的所有事件
从OpenVidu Server获取token
注意:这就是本教程是一个不安全的应用程序的原因。 我们需要向OpenVidu Server请求用户令牌才能连接到我们的会话。 这个过程应该完全在我们的服务器端进行,而不是在我们的客户端。 但是由于本教程中缺少应用程序后端,JavaScript代码本身将对OpenVidu Server执行POST操作
getToken(mySessionId).then(token => {
// See next point to see how to connect to the session using ‘token’
});
现在我们需要一个来自OpenVidu Server的token。 在生产环境中,我们使用 REST API,OpenVidu Java Client 或 OpenVidu Node Client 在应用程序后端执行此操作。 在这里我们已经在一个getToken()方法中实现了向 OpenVidu Server 发送POST请求,这个 getToken 返回一个带有token的Promise。 没有太多细节,这个方法对 OpenVidu Server 执行两个ajax请求,传递 OpenVidu Server secret来验证它们:
首先,ajax执行POST请求到 /api /sessions(我们发送一个customSessionId字段来命名会话,并使用从HTML输入中检索到的mySessionId值)第二个Ajax将POST请求传递给 /api/token(我们发送一个sessionId字段来将该token分配给同一个会话)
您可以在GitHub仓库中详细检查此方法。
使用token连接到session
getToken(mySessionId).then(token => {
session.connect(token)
.then(() => {
document.getElementById(“session-header”).innerText = mySessionId;
document.getElementById(“join”).style.display = “none”;
document.getElementById(“session”).style.display = “block”;
var publisher = OV.initPublisher("publisher");
session.publish(publisher);
})
.catch(error => {
console.log("There was an error connecting to the session:", error.code, error.message);
});
});
我们只需要调用session.connect 并向 OpenVidu Server 传递最近获取到的token。 此方法返回您可以订阅的Promise。
如果订阅成功,我们首先将视图设置为活动视频会话。 然后继续发布我们的摄像头。 为此,我们需要使用 OpenVidu.initPublisher 方法生成发布者,一个显示我们网络摄像头的新HTML视频将被添加到ID为“publisher”的元素内的页面中。
最后比较重要的一点,我们发布这个 publisher 对象需要使用 session.publish。 此时,连接到此会话的其他用户将触发其自己的streamCreated事件,并可以开始观看我们的网络摄像头。
断开会话
session.disconnect();
无论何时我们想要用户断开会话,我们只需要调用session.disconnect方法。 在这里它会调用内部的 leaveSession 函数,当用户点击“LEAVE”按钮时触发。 该功能也将页面返回到“Join session”视图。